干招标代理这行这么多年,说实话,见过太多同行在AI浪潮面前手足无措了。上个月跟几个老哥们儿吃饭,聊到AI这块儿,不少人还搁那儿抱怨“数据从哪来”“语料怎么整”,急得直拍大腿。我说你们急啥,咱这个行业,信息就是命根子,过去靠人脉吃饭,以后得靠数据和AI吃饭,这路数得变变了。后来我就琢磨出来一套法子,专门解决如何高效收集招标代理行业ai语料这个烫手山芋。今儿个就把这些干货掰开了揉碎了讲给你们听,能帮一个是一个。
先给大伙儿说说背景。现在招标代理这个行业,可不是以前那个靠关系就能吃遍天的年代了。2026年1月1日起,《工程建设项目招标代理机构管理办法》(也就是圈里人常说的34号令)正式实施,光凭这个就能看出来,国家对招标代理的规范化要求越来越严了-45。过去机构数量猛涨,全国政府采购代理机构都超过5.9万家了,但质量参差不齐,乱象不少-。与此同时,AI在招投标领域的应用那是突飞猛进——常州的智能分析系统已经检测了一万多份招标文件,发现问题六千多处,准确率高达94%-2;合肥的“青天大模型”把3.5小时的评审压缩到15分钟,效率翻了14倍-14。国家发改委等九部门更是联合发文,明确到2026年底,招标文件检测、智能辅助评标这些场景要在部分省市全覆盖-22。

说这些是为了啥?就是告诉你们,AI不是未来,是现在。而AI要想好用,核心就仨字——喂语料。
第一步:搞清楚语料从哪儿来,别瞎忙活

很多同行上来就问“怎么收集”,但其实第一步应该是“去哪儿收集”。我给大家理了三条路,条条都是我自己踩过坑、趟过路才总结出来的。
第一条路:官方平台,这是最稳妥的粮仓。
中国政府采购网的数据接口,现在已经开放了代理机构信息共享,基本信息、异地评审场所、专职人员、主要业绩都能通过接口直接获取-35。这个接口我是真用过,只要你稍微懂点技术,写几行代码就能自动爬。注意啊,这里要说一句实在话——如何高效收集招标代理行业ai语料,第一条就是“抓官方的接口数据”,这比你自己手动翻公告省了不知道多少工夫。
还有各地的公共资源交易中心,比如江苏的主体信息库,涵盖了招标人、代理机构、投标人等各类参与主体的信息-。这些官方数据的好处是啥?权威。你不用操心数据真假,拿来就能用。
第二条路:专业的招投标数据平台,这是效率最高的。
像千里马招标网这种,人家自己有海量数据采集、清洗、处理的能力,还能做结构化标注,实体识别的准确率能到95%以上-40-40。说人话就是:他们不光帮你把数据收集好了,还帮你把数据整理好了,你要做的就是掏钱买。别心疼那点钱,省下的时间精力足够你干更多有价值的事。
还有剑鱼标讯、世舶科技这些,都提供招投标数据接口对接和挖掘服务--。有人可能会问:“我自己手动收集不行吗?”行,当然行。但我问你,全国每天新增的招投标信息少说几千条,你手动翻到啥时候去?别跟AI比勤奋,你卷不过它。
第三条路:企业自己的历史数据,这是最容易被忽略的宝库。
每家代理机构手里都有一堆历史项目资料——过往的招标文件、投标文件、评审记录、合同文本。这些都是绝佳的语料来源。你说这些数据不规范?那就清洗呗。你说格式不统一?那就标准化呗。这事儿麻烦,但值。
《工程建设项目招标投标AI应用白皮书》里就专门讲了,要“对建筑领域知识、招投标行业知识进行拆解,形成专业知识库”,通过正向知识库学习和专家对模型偏差的修订数据来强化学习,不断提升模型精度-4。说白了,你自己的历史数据,就是你训练AI最宝贵的养料。
第二步:学会用工具收,别再用笨办法
聊到这儿,有人可能要问了:“我数据源知道了,怎么收啊?”我给你们说几个实操的方法,都是我自己用过的,真管用。
方法一:接口批量抓取,一劳永逸。
如果你公司有技术团队,或者你自己会Python,直接对接各地公共资源交易平台的数据接口。中国政府采购网的接口规范里写得清清楚楚,该怎么请求参数、响应参数都有说明-35。写个定时任务,每天自动跑一次,数据就源源不断地进数据库了。我原来也怕麻烦,硬着头皮学了两周Python,现在回头看,那两周的投入简直是性价比最高的学习。
方法二:找第三方数据服务商,省心省力。
适合不想折腾技术的公司。像前面说的那些招投标数据平台,人家已经把数据整理得妥妥的,你付点年费就能用。这钱花得值不值?你就想想——一个专门的数据团队帮你收集、清洗、标注,你的人工成本省了多少?再说了,招标代理机构现在数量这么多,谁能更快用上AI,谁就能在市场里抢到先机。这笔账算不明白的话,说实话,你在这个行业里迟早被淘汰。
方法三:AI辅助清洗,别自己累死。
原始语料收上来了,怎么变“干净”?千里马这种平台自研了NLP引擎,能自动抽取实体、属性和关系,把非结构化文本转成结构化数据-40。你们也可以试试用现成的大模型做预处理,效率比自己标快十倍不止。我有个朋友在招标代理公司干了八年,以前带五个人专门整理文档,现在用AI辅助,一个人顶过去三个人的活,剩下的两个人调去做项目分析,公司营收反而涨了。
再回到刚才那个核心问题——如何高效收集招标代理行业ai语料,答案其实就一句话:官方接口打底,第三方数据补位,自有历史做深,三管齐下,效率想不高都难。
说两个真实案例,让你感受一下什么叫“效率翻倍”
光说不练假把式,我给你们讲两个我身边的真实案例,听完你就知道这事多重要了。
案例一:常州公共资源交易中心。
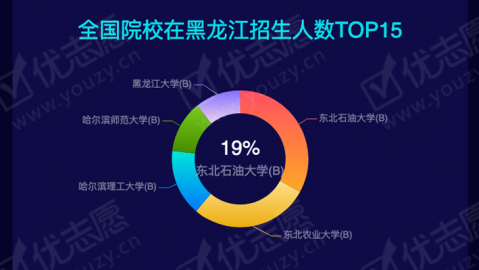
他们的智能分析系统上线后,累计检测了11517份招标文件,发现问题6004处,错误问题标注率达到94.31%-2。你想,如果让人工一份一份去翻,一万人也翻不了这么快。背后的支撑是什么?就是高质量的训练语料——招标文件的规范文本、历史评审记录、法律法规条款。语料收得好,AI才能学得快、判得准。
案例二:合肥的“青天大模型”。
合肥市公管局持续向大模型投喂数据语料,增加算力资源,从电梯项目开始,逐步拓展到土建工程、道路工程、农田水利等12类项目-14。评审效果得到了专家和业主的肯定。AI评审和专家同步做,专家复核后直接运用AI的评分结果,原需3.5小时的评审工作缩至15分钟-14。你品,你细品。这不是PPT上的概念,这是实打实落地的东西。
所以别再问“AI能不能用”这种问题了,应该问“怎么让AI为我所用”。
第三步:语料收集只是第一步,关键是构建专业的知识库
语料收上来了,下一步是啥?建知识库。白皮书里讲得很清楚,AI大模型的构建需要从算力层、数据层、模型层、平台层、应用层五层架构优化-4。落实到咱们实操层面,我给大家几个建议:
一是做专业问答对。 把你日常工作中最常见的问题——比如“招标文件里哪些条款容易引发质疑”“资格预审的流程是什么”——整理成问答对,作为训练语料。这招简单粗暴但管用。
二是构建知识图谱。 把法律法规、项目类型、行业术语、评审标准之间的逻辑关系梳理清楚。千里马的知识图谱技术能做到百亿级的关系构建,咱们小公司用不上那么大,但基本的图谱还是要有的-40。
三是持续迭代。 模型训练不是一锤子买卖,要不断地用专家修订的数据来做强化学习。你在用AI的过程中发现了问题,记录下来,反馈给训练数据,模型会越用越准-4。
说白了,如何高效收集招标代理行业ai语料这件事,本质上考验的是你对这个行业的信息结构的理解深度。你越懂招标代理的业务逻辑,就越知道哪些数据有价值、该去哪儿找。别把AI当万能灵药,也别当洪水猛兽。它就是工具,用好了事半功倍,用不好啥也不是。
写这篇文章的时候,我一边码字一边想,要是五年前有人告诉我这些,我得少走多少弯路。那时候我刚入行,连招标文件和投标书的区别都搞不太清楚,标书的结构都背不溜——商务部分、技术部分、报价部分傻傻分不清-。现在回头看看,真是什么都得交学费。不过现在也不晚,AI这个浪潮才刚开始,大家都还在摸索阶段,谁先跑通,谁就占优势。
有句话说得好:种一棵树最好的时间是十年前,其次是现在。 干就完了。
网友互动问答
网友“安徽老张”问:我们公司规模不大,不到二十个人,哪有预算搞什么AI语料收集?这不是大公司才玩得起的吗?
老张,你这想法我太理解了,因为我刚开始也这么想。但后来我发现,这事儿跟公司大小没关系,跟认知有关系。我给你算笔账哈。咱们招标代理行业,核心业务无非就是帮客户组织招标、编制文件、协调评审。这些活儿,说白了都是信息处理。你一个项目,招标文件要审、投标文件要读、评审结果要写——全是文字工作。
现在市面上,有很多低成本的解决方案。比如说,你不是非要自己从头训练一个大模型,可以直接调用现成的大模型API,按使用量付费。一个月几百块钱,就能让你的团队告别手动翻标书的苦日子。再比如说,第三方数据平台的服务,一年几千到几万不等,关键看你需要什么级别的数据量。比起你多请两个专职人员的人工成本,这已经非常划算了。
而且老张,我跟你说个实话。小公司其实比大公司更需要AI。为什么?大公司人多,分工细,有些活儿靠人堆也能搞定。小公司就那么几个人,每个人都是多面手,精力本来就分散。AI能帮你把那些重复性的、标准化的活儿接过去,让你的人腾出手来做真正有价值的事——比如跟客户沟通、分析项目风险、提供专业的咨询建议。这不正是小公司的核心竞争力吗?
所以我的建议是,先从小处着手。花一两天时间,把你公司近三年的历史项目文档整理一下,标好类别、打好标签。然后找个便宜的API试试水,哪怕只是用AI帮你提取关键信息、生成摘要。你跑通一次,就知道我说的对不对了。别等,等只会让你被甩得更远。
网友“广州小陈”问:语料收集过程中有什么坑要注意?我怕花冤枉钱,更怕数据质量不过关。
小陈问得好,这个问题问到了点子上。我踩过的坑,给大家列一列,能少走一个是一个。
第一大坑:只求数量不求质量。很多人觉得语料越多越好,恨不得把全网的招投标信息都扒下来。但你仔细想想,质量差的语料喂进去,训练出来的AI也是个“学渣”。什么叫质量差?过时的法规条款、残缺的招标文件、有明显错误的评审记录——这些数据不但没用,还会污染模型。我的原则是:宁缺毋滥。先确保你收集的数据是准确的、完整的、有代表性的,再考虑扩大规模。
第二大坑:忽视数据清洗和标注。很多人以为收上来就能直接用,那是做梦。原始语料八成是非结构化的文本,格式五花八门。你得像淘金一样,先把沙子筛掉,才能拿到金子。这事儿没法省,要么自己花功夫,要么花钱找服务商。选哪个看你的情况,但千万别跳过这个环节。
第三大坑:触碰数据安全红线。招投标数据涉及大量的商业敏感信息,甚至是国家秘密。尤其是有些涉密项目的招标文件,传出去是要担法律责任的。在收集和使用语料的过程中,一定要搞清楚哪些数据可以用、哪些不能用、用了要满足什么条件。内网部署、数据脱敏、权限管理——这些不能马虎。2026年国家发改委等九部门的文件里也反复强调了“安全可控”的原则,这不是开玩笑的-22。
第四大坑:闭门造车,不借助行业资源。有些同行喜欢自己从头搞起,其实行业内已经有很多现成的资源可以借力。比如中国政府采购网的数据接口、各地公共资源交易中心的开放数据、行业白皮书里推荐的平台和工具。你自己闷头干三个月,可能不如别人用现成方案三天出效果。何必呢?
总而言之,语料收集这件事,急不得也等不得。慢工出细活,但也要学会借力。多跟同行交流,多看行业报告,多研究官方政策——这些都能帮你少走很多弯路。
网友“山东老王”问:你前面说的那些AI在招投标中的应用,像智能检测、辅助评标这些,离咱们普通代理机构还有多远?现在做是不是太早了?
老王,你要问我这个,我可就不困了。我告诉你,不是太早了,是已经晚了一步。
先说官方动作。2026年4月,国家发改委等九部门刚刚联合印发了《关于加快招标投标领域人工智能推广应用的实施意见》,明确提出了“两步走”路线图-22。2026年底,招标文件检测、智能辅助评标、围串标识别这些场景就要在部分省市实现全覆盖应用-22。注意,是全覆盖,不是试点。这意味着什么?意味着到今年年底,如果你所在的省市被列入先行范围,你的客户、你的对手都在用AI了,你还在用手工干活,你说你竞争得过谁?
再说实际落地的案例。常州的智能分析系统已经给招标代理机构开通了15个账号,系统可以检测招标文件的合规性问题,提示判断依据和修改建议-2-22。苏州也上线了招标文件合规检测的大模型-。深圳更猛,AI资格审查、AI辅助评标、AI识别围串标三大场景全落地了-。这些都不是PPT概念,是真真切切在跑的业务系统。
所以你问现在做是不是太早了?我说,现在开始做,已经比那些先知先觉的晚了半年到一年。再等等,黄花菜都凉了。招标代理行业的门槛会越来越高,光会走流程、填表格的代理机构会被平台直接替代,而真正有价值的是那些懂行业、懂数据、能用AI提升服务深度的代理机构-45。
我不劝你立马投大钱,但我劝你立马行动起来。哪怕只是开个账号体验一下现有的智能工具,哪怕只是把你手里的历史文档整理整理,哪怕只是去了解了解招投标数据接口怎么用。这些都是开始。千里之行始于足下,干就完了,想多了全是问题,做多了全是答案。